正则表达式
.*?匹配任意字符,除了换行符。
``
1 | content = re.findall('豆瓣电影(.*?)TOP250',response.text,re.S) |
.表示除了换行以为所有的字符。^表示匹配的开始,$表示匹配的结尾。
^\d{3}$ 与 \d{3} 所匹配的结果有区别。前者匹配要求极为严格,仅有完整的一行完全符合才可。而后者只要中间有成功 匹配的即可。
验证一年的12个月:”^(0?[1-9]|1[0-2])$”正确格式为:”01”~”09”和”1”~”12”。
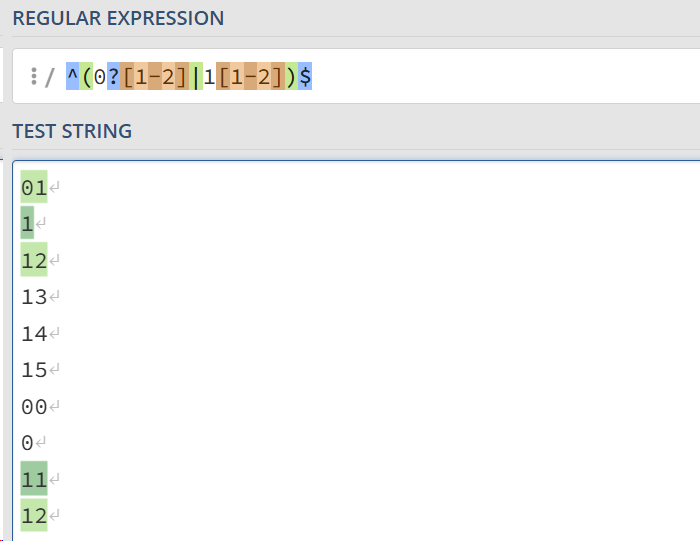
0? 表示此处的0可有可无数量为0-1之间。
[]内表示数字的取值范围,数字间用-隔开。{}用于控制数字的数量,数据间用,隔开。(和):这对括号用来标记一个捕获组,意味着其中的内容可以被捕获或者后续引用。